

Must-haves in your plan and some things to consider!
Disasters and unplanned downtime can strike at any time, costing businesses peace of mind, productivity, and revenue. But when we speak to organizations about how they can protect themselves, they often think about other issues that plague their IT strategy like skill set shortages or hardware gaps in their infrastructure.
It’s easy to become overwhelmed by the numerous aspects of managing IT and IBM i. Everything from applications to infrastructure, backlogs, and new business demands – IT has a lot going on. Most groups fall short or find rudimentary ways to solve High Availability/Disaster Recovery challenges – until it no longer works, or worse. That’s where we come in. We work with customers to create the ideal HA/DR plan for them with the flexibility to scale when it matters most.
As you prepare your HA/DR strategy for 2022, you will want to base your plan on these key points:
- Risk tolerance
- Recovery requirements
- Understanding the difference between various HA/DR strategies to know which will work best for your needs
Recovery Point Objective vs Recovery Time Objective
Understanding the difference between RPO and RTO is necessary to determine your company’s risk tolerance and recovery requirements.
- Recovery Point Objective, or RPO, is how much data your company is willing to have exposed or be at risk.
- Recovery Time Objective, or RTO, is how much downtime your company is willing to endure.
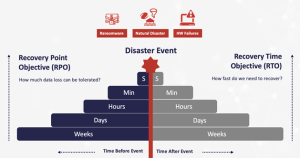
So, an RPO of seven days means that the business has decided that they can survive with losing as much as a week’s worth of data, plus the time needed to rebuild the system (the RTO).
Seven days doesn’t seem like such a short amount of time anymore, does it?
The smaller your RPO and RTO, the more expensive the solution becomes. That’s why it’s critical to understand the real cost and impact of downtime is to your business when planning an HA/DR solution.
High Availability vs Disaster Recovery
Even though they are closely related, High Availability and Disaster Recovery protect your data in different ways. In 2022, there is no excuse for a company of any size to not have a plan for both, and this is especially true for companies on the IBM i platform.
High availability is meant to keep the system available, but it doesn’t necessarily mean in a separate datacenter or a separate site. For many companies it is a local replication that allows for the patching of live systems in the event of a crash. Having two machines side by side in the same data center, with maintenance and backups being conducted between them, is technically a high availability situation. However, if a ransomware attack occurs or a natural disaster strikes that building, it may not be possible to restore one machine from the other.
Disaster Recovery, put simply, is a scenario where you’re restoring your whole system from storage media onto another system. Disaster Recovery is how you get your critical workloads up and running at a remote site if your primary site were to be wiped out.

Tape-Based Solutions
Tape-based backups are the baseline of most Disaster Recovery plans. While some tape-based solutions can be sophisticated, if the tapes are not taken offsite, you’re not necessarily protected. Additionally, the contents of the tapes need to be catalogued and tracked, especially when backups are being conducted often. The RPO of tape-based solutions is defined by the frequency and quality of backups being done.
Virtual Tape Library
Virtual Tape Library, or VTL, is basically a disk-to-disk backup where there’s an appliance that emulates a tape library. The AS/400 system reads what it views as a library with tapes in it, but the backups are, in fact, going to disk. With no physical tapes, the VTL can replicate the data offsite to another appliance via deduplication, which uses a reasonably low amount of bandwidth, while simultaneously conducting local backups.
Pair the right VTL appliance configuration with a disaster recovery contract, or another machine to recover to, and you have a solid Disaster Recovery plan. Many of our customers have chosen a turnkey solution where we remotely manage backups using VTL, replicate them over to our side, provide the infrastructure for recovery, and conduct an annual DR test all on their behalf.
High Availability Strategies
SOFTWARE-BASED HIGH AVAILABILITY
Software-based replication solutions, like Quick-EDD, MIMIX, and iTera, can be expensive and consume a lot of overhead in the system. You need two machines with a reliable network connection and robust processing power, along with ample disk space for journal management. On top of licensing costs, they also require higher levels of technical expertise to tune and manage the solution.
Software-based solutions can also suffer from bandwidth issues, where machines can fall hours behind on backup processes, catching up later when workloads are lighter. Despite these cons, software-based solutions are effective and have their place in the market. But it is not always the “less than one hour” process that people may believe it to be.
HARDWARE-BASED HIGH AVAILABILITY
Our favorite High Availability solution is hardware-based replication on a Storage Area Network (SAN). Every block of data that is in your system is replicated by the SAN “under the covers” at the storage layer, and the IBM i has no idea this is happening. Backup speeds can get down to the point of synchronous mirroring, where data that is being written into the Production storage is also being written into the Target storage. However, faster isn’t always better, and there can be some performance hiccups, depending on how far apart the two data centers are from each other. We see most customers opt for sub-15 minute backups.
A major benefit to SAN-based replication is that backups from Production to Target environments look like full system backups since every data object is replicated. This means we can create additional backups from the Target system with the option to even air gap storage points, giving customers clean recovery points in case there is a ransomware event.
How You Can Protect Your Company’s Data
We often joke with customers that backing up your data to tapes and then storing them in your trunk is not disaster recovery. But all jokes aside, protecting critical business data, and doing so properly, is a requirement that IBM i shops need to tackle right now.
This is especially true considering man-made disasters are increasingly becoming as common as natural ones. In 2021 alone, we assisted in 25-30 recoveries from ransomware, and we expect it to be the most ubiquitous disaster situation in 2022. It’s therefore important to keep multiple point-in-time replicas to ensure you have a clean set of data and applications to restore from. Hence the need to air gap early and often.
The first step in searching for the right HA/DR plan is to consider:
- How quickly could your company recover if an unplanned incident occurred?
- Are you confident that you could even restore all your systems and data?
- What impact would a disaster or downtime have on your business?
Or, if your company already has an HA/DR solution in place, how recently has it been tested? Abacus can help answer these questions, and more; we know how to set up HA and DR systems, and we have managed services to help you run this – we can even host your IBM i in the cloud as part of your HA/DR setup. Schedule a free consultation today to build a great HA/DR strategy for 2022. Contact us at info@freschesolutions.com

